Lecture 10: Sequential Models
Introducing State Space Models and Kalman filters.
Mixture Models Review and Intuition to State Space Models
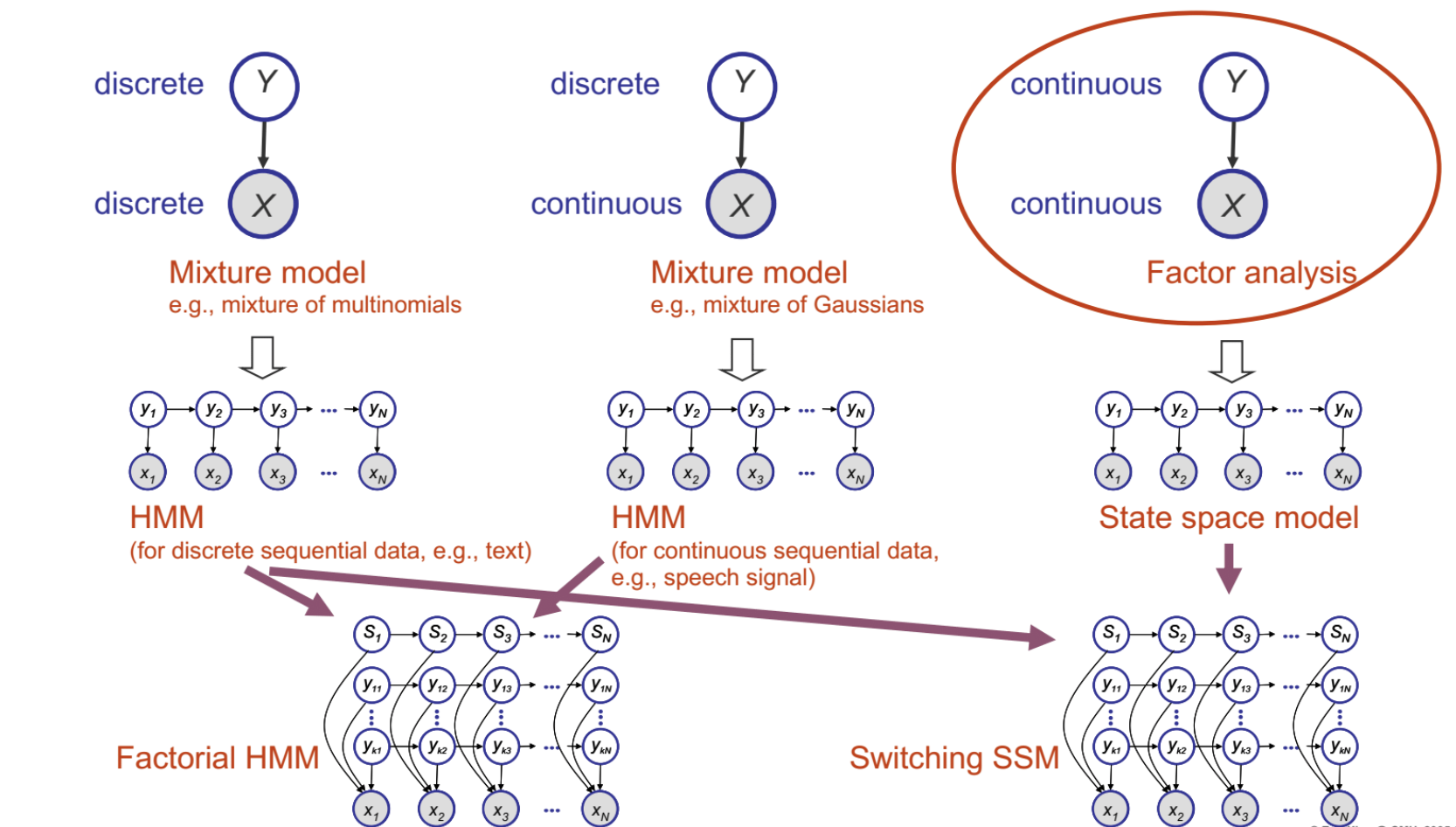
- Mixture model has the observation X and their corresponding hidden latent variable Y which indicates the source of that observation X. Observation X can be discrete like word frequency, or continuous like temperature. Variable Y denotes which mixture/distribution X comes from. When both X and Y are continuous, it is called factor analysis.
- The advantage with mixture models is that smaller graphs (mixture models) can be taken as building blocks to make bigger graphs (HMMs)
- Some common inference algorithms for HMMs can range from inferring on one hidden state, all hidden states, and even the most probable sequence of hidden states. Example algorithms are Viterbi algorithm, Forward/Backward algorithm, Baum-Welch algorithm.
- All the above algorithms have a counterpart in State Space models - despite the mathematical technique being different, they have the same essence. A similarity to the above algorithms that it shares is that it can be broken down into local operations/subproblems and continuously built to the whole solution. We will further explain in the coming sections.
- Stories/Intuitions for the various models
- HMM - Dishonest casino story
- Factorial HMM - Multiple dealers at the dishonest casino
- State Space Model (SSM) - X – Signal of an aircraft on the radar, Y – actual physical locations of the aircraft
- Switching SSM - multiple aircrafts (State S is the indicator of which aircraft is appearing on the radar)
Basic Math Review
A multivariate Gaussian is denoted by the following PDF -
A Joint Gaussian is denoted by -
Given the joint distribution, we can write -
Matrix inverse lemma -
- Consider a block partitioned matrix M =
\begin{bmatrix} E & F \\ G & H \end{bmatrix} - First we diagonalize M -
\begin{bmatrix} I & -FH^{-1} \\ 0 & I \end{bmatrix}\begin{bmatrix} E & F \\ G & H \end{bmatrix}\begin{bmatrix} I & 0 \\ -H^{-1}G & I \end{bmatrix} = \begin{bmatrix} E-FH^{-1}G & 0 \\ 0 & H \end{bmatrix} - This is called the Schur's complement -
M/H = E-FH^{-1}G - Then we inverse using the formula -
\begin{aligned} XYZ = W \implies Y^{-1} = ZW^{-1}X \implies M^{-1} = \begin{bmatrix} E & F \\ G & H \end{bmatrix}^{-1} = \begin{bmatrix} I & 0 \\ -H^{-1}G & I \end{bmatrix}\begin{bmatrix} (M/H)^{-1} & 0 \\ 0 & H^{-1} \end{bmatrix}\begin{bmatrix} I & -FH^{-1} \\ 0 & I \end{bmatrix} \\ = \begin{bmatrix} (M/H)^{-1} & -(M/H)^{-1}FH^{-1} \\ -H^{-1}G(M/H)^{-1} & H^{-1} + H^{-1}G(M/H)^{-1}FH^{-1} \end{bmatrix} \\ = \begin{bmatrix} E^{-1} + E^{-1}F(M/E)^{-1}GE^{-1} & -E^{-1}F(M/E)^{-1} \\ -(M/E)^{-1}GE^{-1} & (M/E)^{-1} \end{bmatrix} \end{aligned} - Hence, by matrix inverse lemma,
(E - FH^{-1}G)^{-1} = E^{-1}+ E^{-1}F(H-GE^{-1}F)^{-1}GE^{-1}
Review of Basic matrix algebra -
- Trace -
tr[A]^{def} = \Sigma_i a_{ii} - tr[ABC] = tr[CBA] = tr[BCA]
- Derivatives -
\begin{aligned} \frac{\partial}{\partial A}tr[BA] = B^{T} \\ \frac{\partial}{\partial A}tr[x^{T}Ax] = \frac{\partial}{\partial A}tr[xx^{T}A] = xx^{T} \end{aligned} - Derivates -
\frac{\partial}{\partial A}log|A| = A^{-1}
Factor analysis
Imagine a point on a sheet of paper
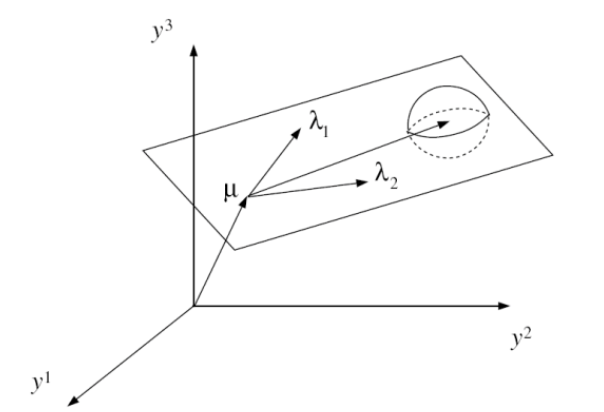
We know that, a marginal gaussian (p(X)) times a conditional gaussian (p(Y|X)) is a joint gaussian, and a marginal (p(Y)) of a joint gaussian (p(X, Y)) is also a gaussian. Hence, we can compute the mean and variance of Y. Assuming noise W is uncorrelated with the data,
Hence, the marginal density for factor analysis (Y is p-dim, X is k-dim):
We can also say, that the effective covariance matrix is a low-rank outer product of two long skinny matrices plus a diagonal matrix. In other words, factor analysis is just a constrained Gaussian model.
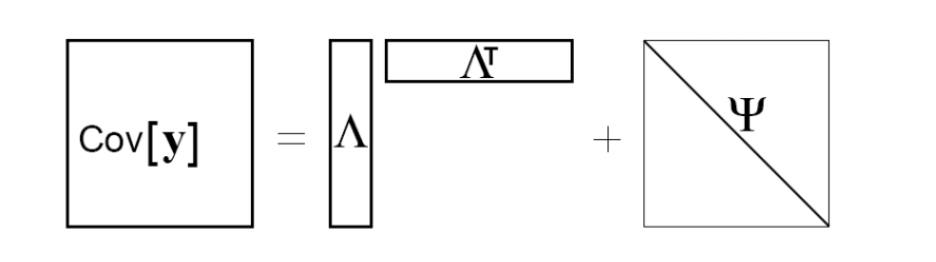
We will now analyse the Factor analysis joint distribution assuming noise is uncorrelated with the data or the latent variables -
The distributions as we derived/assumed above are-
Now we can say -
Learning in Factor Analysis
The inference problem, as shown above can be thought of as a linear projection since the posterior covariance ($V_{1|2}$ above) does not depend on the observed data $y$ and the posterior mean $\mu_{1|2}$ is just a linear operation.
The learning problem in Factor Analysis corresponds to learning the parameters of the model, i.e., the loading matrix $\Lambda$, manifold center $\mu$ and the diagonal covariance matrix of the noise, $\Psi$. As always, we will solve this problem by maximizing the log-likelihood of the observed data, i.e. \((\mu^*, \Lambda^*, \Psi^*) =\) argmax \(\ell(\mathcal{D} ; \mu, \Lambda, \Psi)\).
Thanks to the derivation above, we have a closed-form expression for the incomplete log likelihood of the data, i.e. $\mathcal{D} = \text{\textbraceleft} y^{(i)} : i=1,…,n \text{\textbraceright} $, as shown below:
Estimation of $\mu$ is straightforward, however $\Lambda$ and $\Psi$ are tightly coupled non-linearly in log-likelihood. In order to make this problem tractable, we will use the same trick used in Gaussian Mixture Models, i.e., optimize the complete log-likelihood using Expectation Maximization (EM) algorithm.
In the E-step of the EM procedure, we compute the expectation of the complete log-likelihood wrt the posterior, i.e., $p(x|y)$:
Further, we use the posterior density calculations in the previous section to obtain the different expectations in the equation above:
In the M-step, we take derivatives of the expected complete log-likelihood calculated above wrt the parameters and set them to zero. We shall use the trace and determinant derivative rules derived above in this step.
In a similar fashion,
It should be noted that this model is “unidentifiable” in the sense that different runs for learning parameters for the same dataset are not guaranteed to obtain the same solution. This is because there is degeneracy in the model, since $\Lambda$ only occurs in the product of the form $\Lambda \Lambda^T$, making the model invariant to rotations and axis flips in the latent space. To see this more clearly, if we replace $\Lambda$ by $\Lambda Q$ for any orthonormal matrix $Q$, the model remains the same because \((\Lambda Q)(\Lambda Q)^T = \Lambda (QQ^T) \Lambda^T = \Lambda \Lambda^T\).
Introduction to State Space Models (SSM)
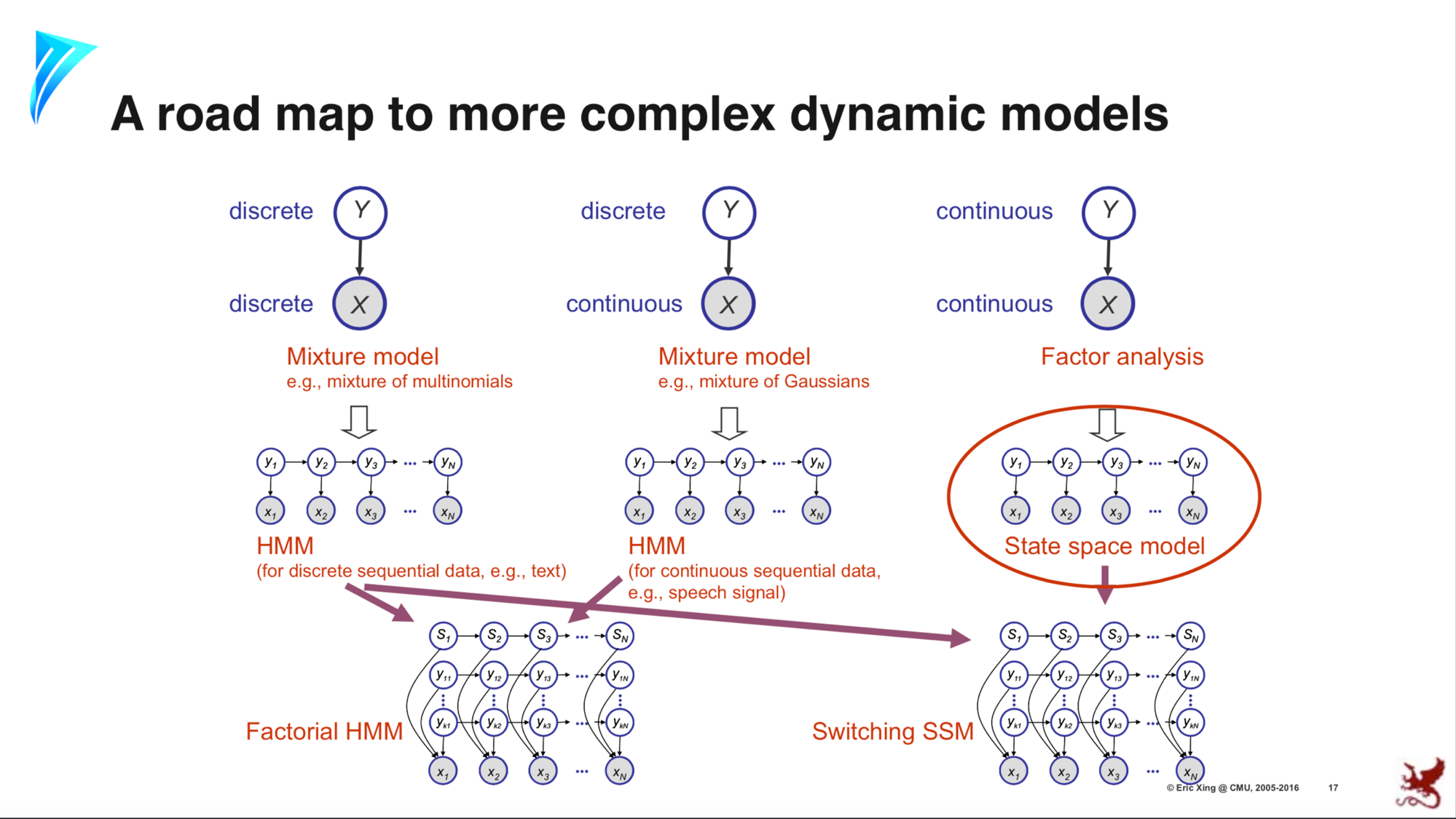
In the figure above, the dynamical (sequential) continuous counterpart to HMMs are the State Space Models (SSM). In fact, they are the sequential extensions of Factor Analysis discussed so far. SSM can be thought of as a sequential Factor Analysis or continuous state HMM.
Mathematically, let $f(\cdot)$ be any arbitrary dynamic model, and let $g(\cdot)$ be any arbitrary observation model. Then, we obtain the following equations for the dynamic system:
Here $w_t \sim \mathcal{N}(0, Q)$ and $v_t \sim \mathcal{N}(0, R)$ are zero-mean Gaussian noise. Further, if we assume that $f(\cdot)$ and $g(\cdot)$ are linear (matrices), then we get equations for a linear dynamical system (LDS):
An example of an LDS for 2D object tracking would involve observations $y_t$ to be 2D positions of the object in space and $x_t$ to be 4-dimensional, with the first two dimensions corresponding to the position and the next two dimensions corresponding to the velocity, i.e., the first derivative of the positions. Assuming a constant velocity model, we obtain the state space equations for this model, as shown below:
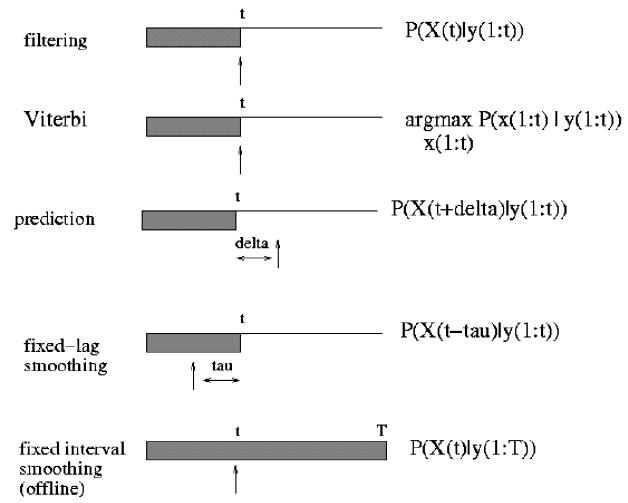
There are two different inference problems that can be considered for SSMs:
-
The first problem is to infer the current hidden state ($x_t$) given the observations up to
the current time $t$, i.e., $y_1, y_2, ..., y_t$. This problem is analogous to the forward
algorithm in HMMs, is exact online inference problem, known as the $\textbf{Filtering}$ problem and will be discussed next.
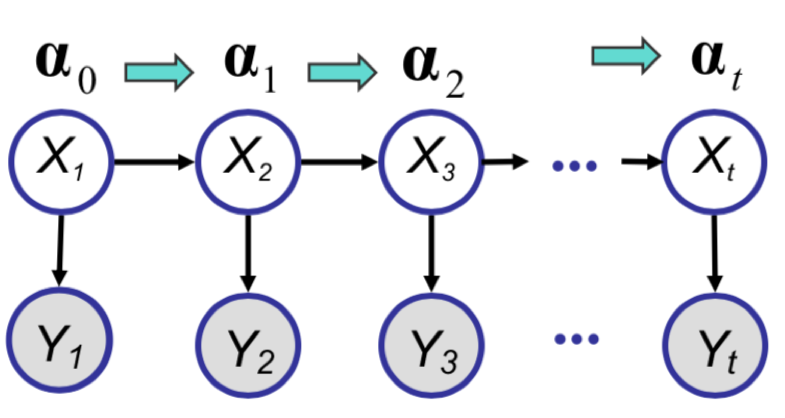
Filtering -
The second problem is the offline inference problem, i.e., given the entire sequence $y_1, y_2, ..., y_T$,
estimate $x_t$ for $t < T$. This problem, called the $\textbf{Smoothing}$ problem, can be solved using
the Rauch-Tung-Strievel algorithm and is the Gaussian analog of the forward-backward (alpha-gamma) algorithm
in HMMs.
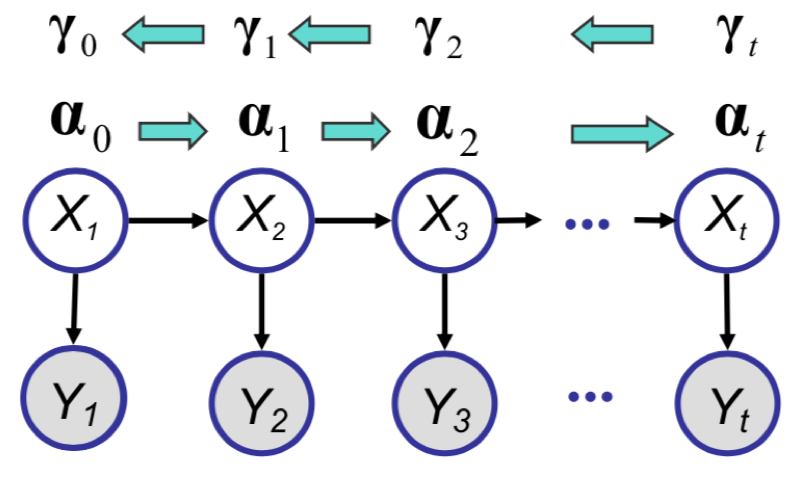
Smoothing
Kalman Filter
The Kalman Filter is an algorithm analogous to the forward algorithm for HMM. For the state space model (SSM), the goal of Kalman filter is to estimate the belief state $P(X_{t}|y_{1:t})$ given the data ${y_{1},…,y_{t}}$. To do so, it mainly follows a recursive procedure that includes two steps, namely time update and measurement update. Here, we are going to derive the two steps.
Derivation
- Time Update:
(1) Goal: Compute $P(X_{t+1}|y_{1:t})$ (the distribution for $X_{t+1|t}$) using prior belief $P(X_{t}|y_{1:t})$ and the dynamical model $P(X_{t+1}|X_{t})$.
(2) Derivation: Recall that the dynamical model states that \(X_{t+1}=AX_{t}+Gw_{t}\) where $w_{t}$ is the noise term with a Gaussian distribution $\mathcal{N}(0; Q)$. Then, we can conpute the mean and variance for $X_{t+1}$ using this formula.
For the mean, we have:
For the variance, we have:
- Measurement Update:
(1) Goal: Compute $P(X_{t+1}|y_{1:t+1})$ using $P(X_{t+1}|y_{1:t})$ computed from time update, observation $y_{t+1}$ and observation model $P(y_{t+1}|X_{t+1})$.
(2) Derivation: The key here is to first compute the joint distribution $P(X_{t+1},y_{t+1}|y_{1:t})$, then derive the conditional distribution $P(X_{t+1}|y_{1:t+1})$. Recall that the observation model states that \(y_{t}=CX_{t}+v_{t}\) where $v_{t}$ is the noise term with a Gaussian distribution $\mathcal{N}(0; R)$. We have already computed the mean and the variance of $X_{t+1|t}$ in the time update. Now we need to compute the mean and the variance of $y_{t+1|t}$ and the covariance of $X_{t+1|t}$ and $y_{t+1|t}$.
For the mean of $y_{t+1|t}$, we have:
For the varaince of $y_{t+1|t}$, we have:
For the covaraince of $X_{t+1|t}$ and $y_{t+1|t}$, we have:
Hence the joint distribution of $X_{t+1|t}$ and $y_{t+1|t}$ is:
Finally, to compute the conditional distribution of a joint Gaussian distribution, we recall the formulas as:
Plugging in results from above we have the conditional distribution of $P(X_{t+1}|y_{1:t+1})$ as:
where $K_{t+1} = P_{t+1|t}C^T(CP_{t+1|t}C^T+R)^{-1}$ is referred to as the Kalman gain matrix.
Example
We now see an example of Kalman filter on a problem on noisy observations of a 1D particle doing a random walk. The SSM is given as:
where $w \sim \mathcal{N}(0; \sigma_{x})$ and $v \sim \mathcal{N}(0; \sigma_{y})$ are noises. In other words, $A=G=C=I$. Thus, using the update rules derived above we have that at time t:
As demonstrated in the figure below, given prior belief $P(X_0)$, our estimate of $P(X_1)$ without an observation has the same mean and larger variance as shown by the first two lines in equations above. However, given an observation of $2.5$, the new estimated distribution shifted to the right accoding to last three lines of equations above.
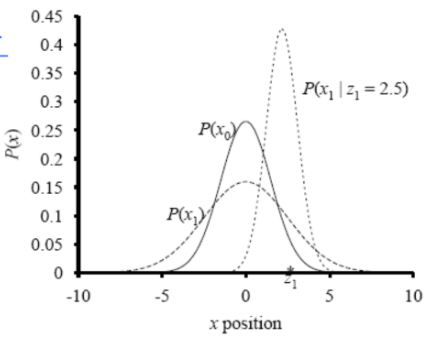
Complexity of one KF step:
Let $X_t \in R^{N_x}$ and $Y_t \in R^{N_y}$
Predict step: $P_{t+1|t} = AP_{t|t}A + GQG^T$
This invloves matrix multiplication of $N_x$ x $N_x$ matrix with another $N_x$ x $N_x$ matrix, hence the time complexity is $O(N_{x}^{2})$
Measurement Updates: $K_{t+1} = P_{t+1|t}C^T(CP_{t+1|t}C^T + R)^{-1}$
This invloves a matrix inversion of $N_y$ x $N_y$, hence the time complexity is $O(N_{y}^{3})$
Overall time = max{$N_{x}^{2},N_{y}^{3}$}
Rauch-Tung-Strievel
The Rauch-Tung-Strievel algorithm is a Gaussian analog of the forwards-backwards(alpha-gamma) algorithm for HMM. The intent is to estimate $P(X_t|y_{1:T})$.
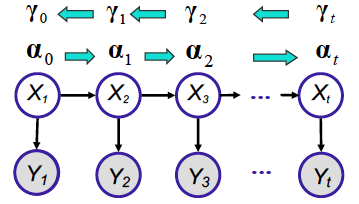
Since, $P(X_t|y_{1:T})$ is a Gaussian distribution, we intend to derive mean $X_{t|T}$ and variance $P_{t|T}$.
Let’s first define the joint distribution $P(X_{t},X_{t+1}|y_{1:t})$.
where m and V are mean and covariance of joint distribution respectively.
We are going to use a neat trick to arrive at the RTS inference.
$E[X|Z] = E[E[X|Y,Z]|Z]$
$Var[X|Z] = Var[E[X|Y,Z]|Z] + E[Var[X|Y,Z]|Z]$
Now, applying these results to our problem:
$X_t$ is independent of $X_{t+2:T}$ given $X_{t+1}$, so:
Using the formulas for the conditional Gaussian distribution:
Similarly,
where, $L_t = P_{t|t}A^TP^{-1}_{t+1|t}$
Learning State Space Model
Likelihood:
E-step: Compute $<X_tX_{t-1}^T>$, $<X_tX_t^T>$ and $<X_t>$ using Kalman Filter and Rauch-Tung-Strievel methods.
M-step: Same as explained in the Factor Analysis section.
Non-Linear Systems
In some of the real world scenarios, the relation between model states as well as states and observations may be non-linear. This renders a closed form solution to the problem almost impossible. In recent works, this non-linearity relation is captured using deep neural networks and stochastic gradient descent based methods are used to obtained the solutions. These state space models can be represented as:
$x_t = f(x_{t-1}) + w_t$
$y_t = g(x_t) + v_t$
Since the effect of the noise covariance matrices Q and R remains unchanged due to non-linearity, they have been omitted from the discussion for convenience.
An approximate solution without using deep neural networks is to express the non-linear functions using Taylor expansion. The order of expansion depends on the use case and the extent of the non-linearity. These are referred to as Extended Kalman Filters. The following equations show the second order Taylor expansion for Extended Kalman Filters:
where,
Online vs Offline Inference
Online Inference: Inference methods that are based on looking only at the observations till the current time-step. They generally take the form $P(X|y_{1:t})$. The inference objective may vary depending on the algorithm. Eg, Kalman Filter.
Offline Inference. Inference methods than consider all the observations from all the time-steps. The take the form $P(X|y_{1:T})$. Eg, Rauch-Tung-Strievel smoothing.
Recursive Least Squares and Least Mean Squares
Consider a special case where the state $x_t$ remains constant while the observation coefficients ($C$) vary with time. In this scenario, observations are affected by the coefficients rather than the state itself. This turns the estimation of the state into a linear regression problem.
Let $x_t = \theta$ and $C = x_t$ in the KF update equation. Then we can represent the observation models as
$y_t = x_t\theta + v_t$
which takes exactly the form of a linear regression problem to estimate $\theta$.
Now, using the Kalman Filter idea we can formulate the update equation for this problem as:
This is the recursive least squares algorithm as one can see that the update term takes the form of the derivative of square of the difference. If we treat $\eta = P_{t+1}R^{-1}$ as a constant this exactly becomes least mean squares algorithm.