Lecture 15: Statistical and Algorithmic Foundations of Deep Learning
How graphical models relate to deep learning.
Neural Network Review
The Perceptron/Perceptron Learning Algorithm
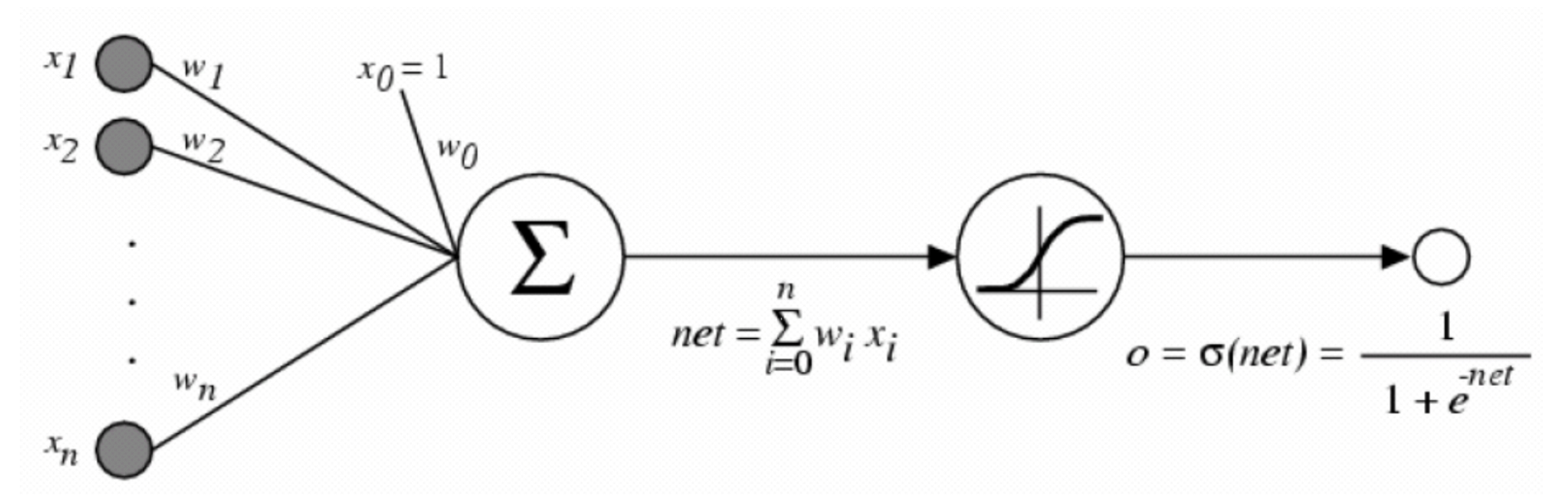
The most simple neural network is the perceptron. It applies a weighted sum to its inputs, and applies a sigmoid function to this sum (shown as the $ \sigma $ below).
This learning algorithm can be used to maximize a conditional likelihood, $y=f(x)+\epsilon$, such that
\[\bar{w} = \arg \min_{\bar{w}} \sum_i \frac{1}{2} (y_i - \hat{f} (x_i ; w))^2\]Thus, we can find the gradient of this loss function with respect to a weight $w_j$:
\[\begin{aligned} \frac {\partial E_D [\bar{w}]}{\partial w_j} &= \frac {\partial}{\partial w_j} \frac{1}{2} \sum_d (t_d - o_d)^2 \\ &= \frac{1}{2} \sum_d 2 (t_d - o_d) \frac {\partial}{\partial w_j} (t_d - o_d) \\ &= \sum_d (t_d - o_d) \frac {- \partial o_d }{\partial w_j} \\ &= - \sum_d (t_d - o_d) \frac { \partial o_d }{\partial net_d} \frac { \partial net_d }{\partial w_i} \\ &= - \sum_d (t_d - o_d) o_d (1-o_d) x_d^i \\ \end{aligned}\]So, $\nabla E_d [\bar{w}] = - (t_d - o_d) o_d (1-o_d) \bar{x_d}$. Thus, the incremental perception learning algorithm does the following (with a learning rate of $\eta$):
For each training example $d$ in $D$:
- compute gradient $\nabla E_d [\bar{w}]$
- $\bar{w} = \bar{w} - \eta \nabla E_d [\bar{w}]$
This can also be done in batch mode, by averaging gradients across multiple examples.
Backpropagation using a computational graph
This learning algorithm gets slightly more complicated when we introduce hidden units, circled in yellow below:
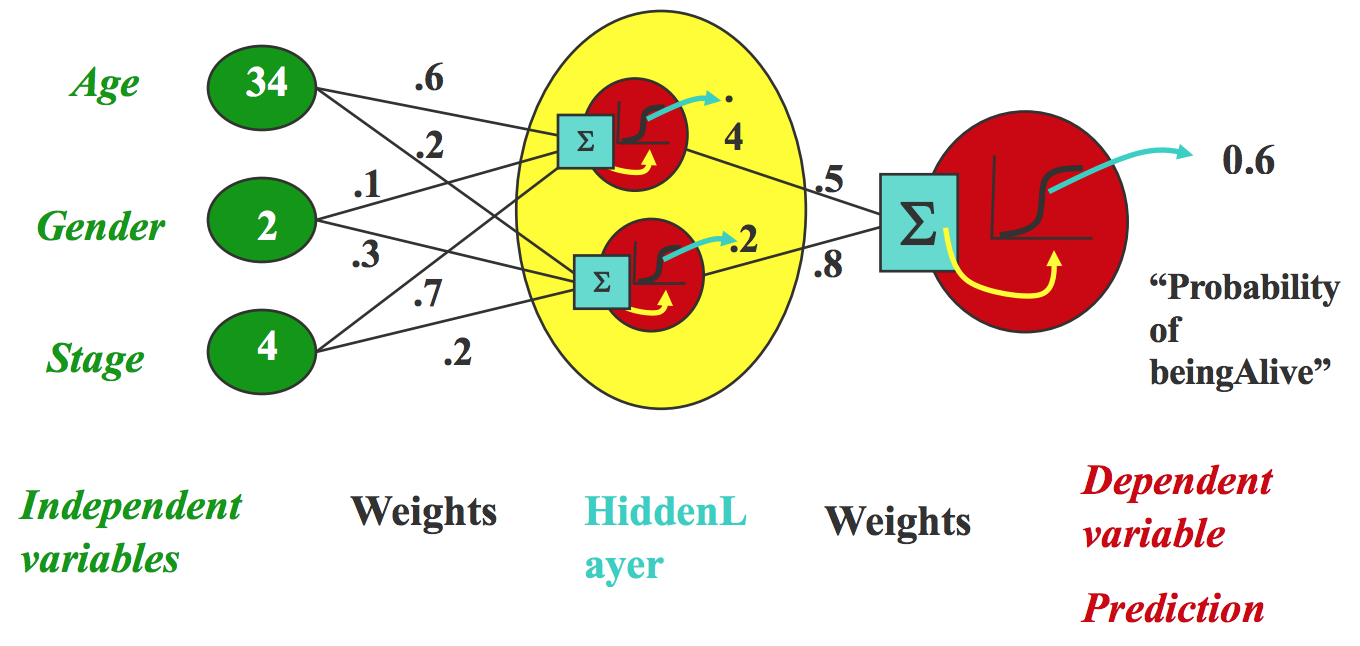
Unlike neurons in the final layer, hidden units do not correspond to a particular class. We train the weights in these layers using backpropagation, or “reverse-mode differentiation”. First, we can build a computaitonal graph, where $x$ is the input and $f(x)$ is the output, and nodes 2, 3, and 4 are the intermediate computations:
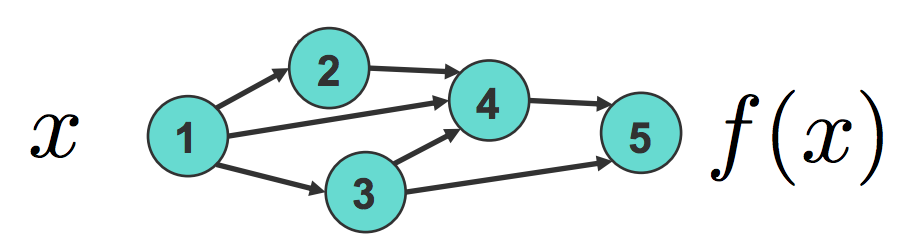
By applying the chain rule, we can derive:
\[\frac {\partial f_n}{\partial x} = \sum_{i_1\in \pi(n)} \frac {\partial f_n}{\partial f_{i_1}} \frac {\partial f_{i_1}}{\partial x} = \sum_{i_1\in \pi(n)} \frac {\partial f_n}{\partial f_{i_1}} \sum_{i_2\in \pi(i_1)} \frac {\partial f_{i_1}}{\partial f_{i_2}} \frac {\partial f_{i_2}}{\partial x} = \cdots\]This algorithm of recursively calling the chain rule is called backpropagation, and we can use it to train most deep networks, even though we don’t have a target for the hidden units.
Modern building blocks of deep networks
Most deep networks are composed of many simple building blocks:
- Layers, specifying the architecture and type of connections
- Fully connected
- Convolutional and pooling
- Recurrent
- Residual Layers
- etc.
- Activation functions, that go in between these layers
- Linear: $f(x) = x$
- ReLU: $f(x) = max(0, x)$
- Sigmoid: $f(x) = \sigma(x) = \dfrac{1}{1+e^{-x}}$
- tanH: $f(x) = \text{tanh}(x) = \dfrac{e^x - e^{-x}}{e^{x} + e^{-x}}$
- etc.
- Loss functions, which we are trying to minimize (can have many in one network)
- Cross-entropy loss
- Mean squared error
- etc.
Feature learning
Often one important goal of deep networks is to learn a good representation of the input. Deep networks are often good at doing this, and can attempt to get a “disentangled” representation, i.e. amenable to linear separation, as shown below:
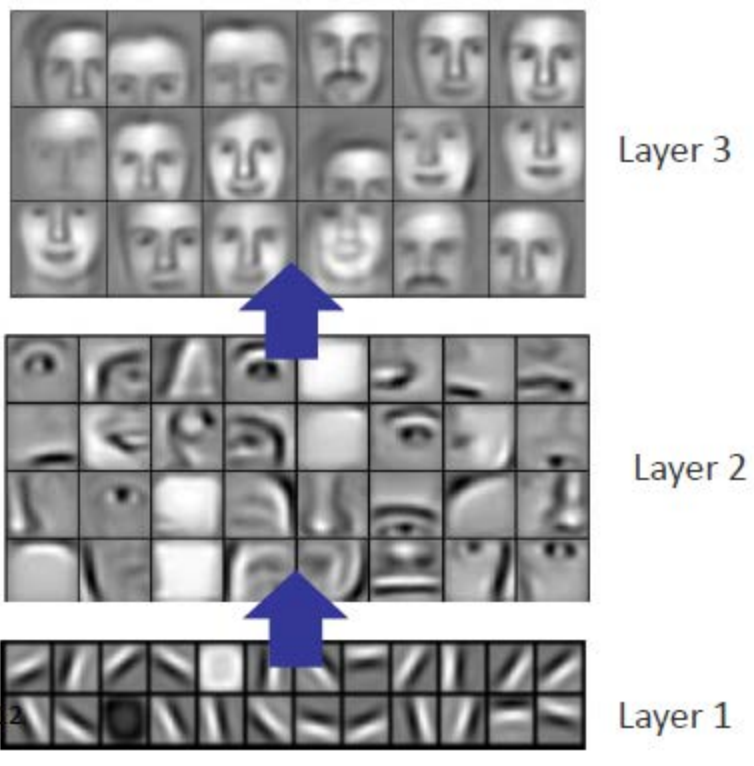
Because DNNs have this property, it is often possible to transfer representations and use pretrained deep neural networks as feature extractors for new tasks. In these cases, the activations of intermediate layer $h_j$ in model $M$ (trained on task $A$) are used to generate representations for a different task $B$. Because these representations might be linearly separable, it typically suffices to train a linear model, or shallow neural network on the featurized data. The most common example of this is ImageNet, and models trained on ImageNet (i.e. vgg16) are typically good feature extractors for other vision based tasks.
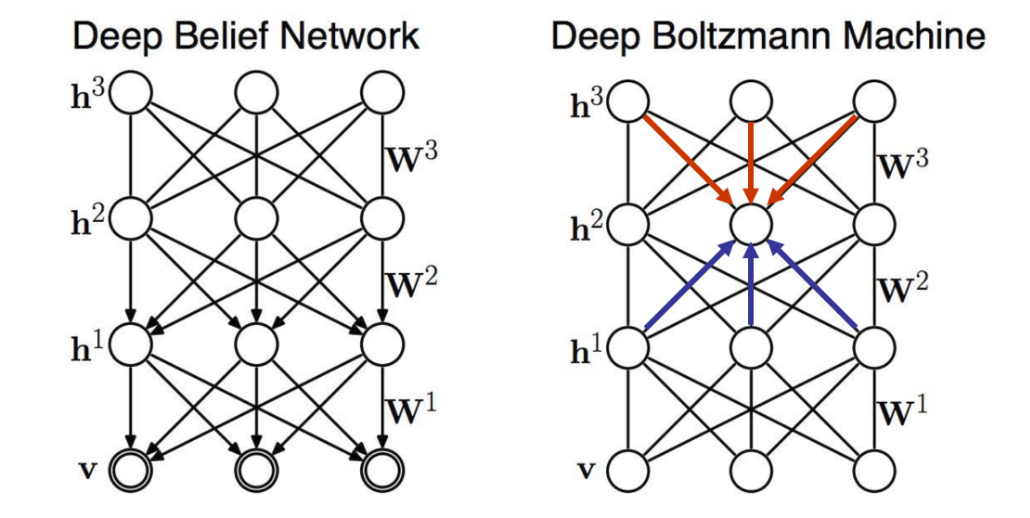
Graphical Models vs. Deep Networks
While the two paradigms appear to share the same graphical structure on the surface, juxtaposing their properties point out subtle differences between them.
| Feature | Graphical model | Neural Networks |
|---|---|---|
| Representation | It encodes prior meaningful knowledge. Every node has a meaning and edges represent the relationship between the variables. | They are learnt in a way that optimizes the end metric. The meaning of intermediate nodes are typically not the focus. |
| Learning and inference | Involves well studied algorithms like MCMC, VI and message passing. | Learning primarily involves gradient descent. Inference just involves a forward pass through the network. |
| Structural utility | Graphs help monitor theoretical and empirical behaviour of inference | Networks facilitate the organization of computational operations |
Tradeoffs: As with any modeling strategy, there are inherent tradeoffs between graphical models and neural networks. Graphical models allow us to directly encode prior knowledge about the world into the structure of the model (i.e. latent states), enabling us to enforce some weak notions of causality. However, this requires domain expertise, and assumes that the structure enforced on the model is the most natural/well suited for the task. In contrast, neural networks learn their own latent representations, by minimizing loss in an end-to-end manner. As a result, they may be seen as learning a more ‘efficient’ representation. However, this approach can require signicant amounts of data, which may not always be available.
Thus, we see that the graphs in a graphical model represent the model itself whereas it just represents computation in the case of a deep network.
Some neural networks can be completely understood as a conventional graphical model. A few examples are examined below -
1.Restricted Boltzmann Machines
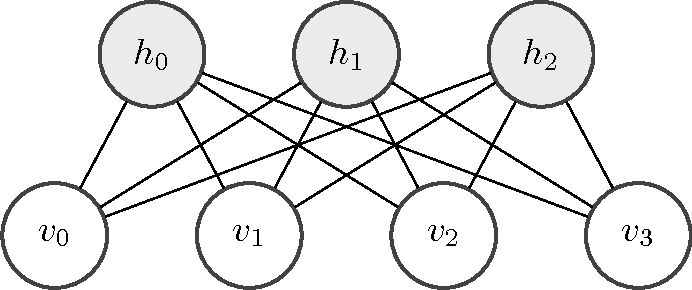
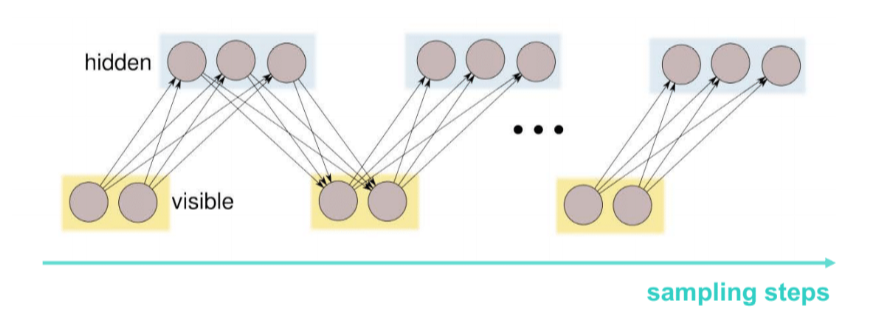
Overview: RBMs are represented by undirected bipartite graphs, with one “visible” layer and a second “hidden” layer. There are no connections between nodes in the same layer (in contrast to unrestricted Boltzmann machines, which permit connections between hidden units).
Learning: We compute a loss function by marginalizing over all the hidden variables and taking the derivative w.r.t weights:
\[\log L(v) = \log \sum_{h} \exp(\sum_{i,j} w_{ij} v_{i} h_{j} + \sum_{i} b_{i}v_{i} + \sum_{j} c_{j} h_{j} - \log(Z))\] \[\frac{\partial \log L(v)}{\partial w_{ij}} = \sum_{h} P(h | v) \frac{\partial}{\partial w_{ij}} P(v,h) - \sum_{v,h} P(v,h) \frac{\partial}{\partial w_{ij}} P(v,h)\]or alternatively, as: \(\dfrac{\partial}{\partial w_{ij}} \log L(v) = \mathbb{E}_{P(h|v)} \bigg[\dfrac{\partial}{\partial w_{ij}} P(v, h)\bigg] - \mathbb{E}_{P(v, h)} \bigg[\dfrac{\partial}{\partial w_{ij}} P(v, h)\bigg]\)
Of the two terms in the loss above:
- The first term is the expectation taking over the conditional of the hidden given the observed, i.e. we average over the posterior. This is computed via sampling, which is exact (the RBM factorizes over $h$ given $v$). In neural network literature, this is also called the clamped/ wake/ positive phase.
- The second term is the expectation taken over all random variables (both hidden and observed), i.e we average over the joint. This is also computed sampling, but requires the iterative Gibbs sampling algorithm. Consequently, it’s far more expensive (computationally) and slow to converge. In neural network literature, this is called the the unclamped/ sleep/ negative phase.
2. Sigmoid Belief Networks
SBNs consist of stacks of directed linear layers combined via non-linear sigmoid activation functions. The intermediate meaning of the hidden layers are typically ignored and so even though they synactically represent graphical models, operationally they begin to deviate. Operationally treating them as graphical models, leads to inefficient inference because of the implicit “explaining away” phenomenon as when we want to infer a hidden variable, it is coupled with all other hidden random variables in that layer. This stands in contrast to the RBM case because d-seperation in the RBM graph meant that the hidden random variables are independent given the other layer. Also, unlike the RBM, computing the conditional does not involve a negative phase.
We now connect our discussions of inference in the SBN and the RBM. Recall that for the gradient of the sleep phase of loss function, we could sample the joint using Gibbs procedure which alternates between different subsets of varaibles. While the vanilla Gibbs sample requires sampling every single random variable one by one given all other points, a broader idea, called block Gibbs sampling which groups the variables into arbitrary blocks and samples on the block given everything else. In the case of the RBM, we consider the two layers as two blocks and hence, sampling involves alternating between the two layers.